ディープラーニング設計について
続いては、設計時に必要な考え方についてまとめます。
目次
学習の円滑化1(パラメータ(重み)の初期値について)
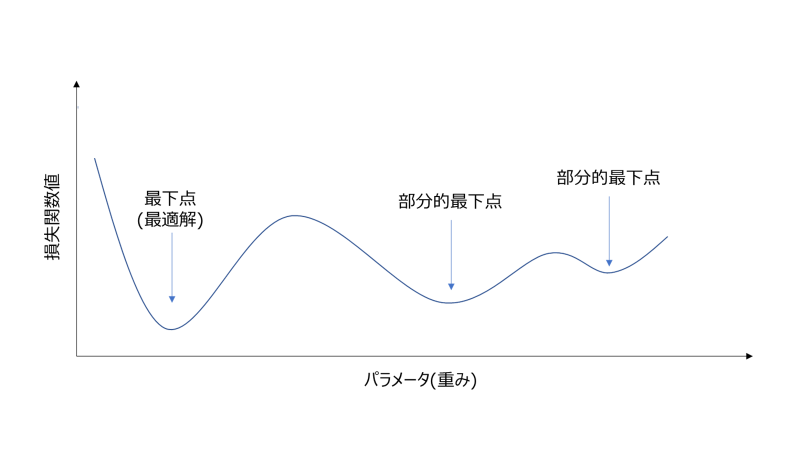
ディープラーニングでは、SGDなどのパラメータ更新アルゴリズムを駆使して最適解を目指します。
よって、重み更新の初期値はかなり重要です。もし最適解に近い重みからスタートできれば、更新回数は少なく・最適解へたどり着ける可能性もずっと高くなります。
図:ディープラーニングの重みと損失関数値の関係
初期値設計の考え方にHeの初期化、Xavierの初期化(Glorotの初期化)と呼ばれる方法があり、
ここで紹介をしていきますが、まずはやってはいけない初期値設計について簡単に説明します。
- すべての重みを均一にする
もしこのように初期値を設定してしまうと、すべての重みが連動して同じ値に動く可能性が生じます。
これの何がいけないかというと、すべてが連動して動いてしまうとそれがあたかも一つの変数のように動いてしまうという点です。
ディープラーニングの特徴である柔軟性を失いかけるので、重み初期値をランダムに設定するということは大変重要です。
- 勾配消失問題
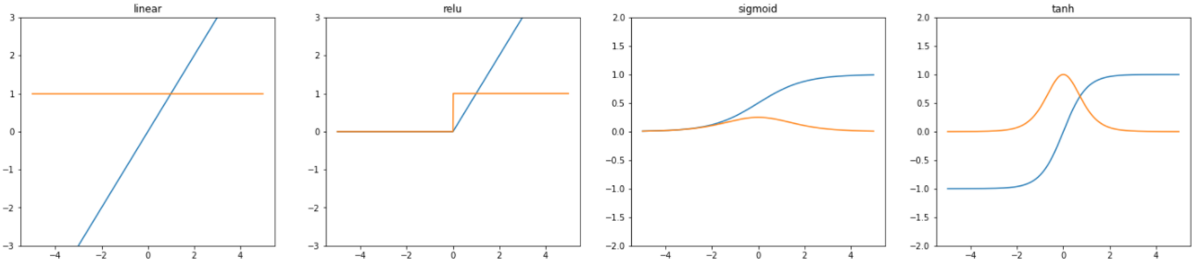
活性化関数としてシグモイド関数、ハイパボリックタンジェントを使用する場合、勾配>0となる場所は限られてきます。
初期値に勾配=0となる個所を選択してしまうと、勾配消失問題を引き起こし、パラメータ更新が行われないという問題が生じます。
上記より、勾配が>0となる個所を選択すれば良いということになりますが、紹介した活性化関数では、勾配>0となる個所は限られており、先程説明したような重みが一体化して動いてしまうという現象を引き起こしかねないので、注意が必要です。
図:代表的な活性化関数のグラフ(左から順に線形関数、ReLu関数、シグモイド関数、ハイパボリックタンジェント)
オレンジ:活性化関数を微分したもの(導関数)
学習の円滑化2(BatchNormalization)
各層のアクティベーション分布がある程度の広がりを持つように重みの初期値を設定しました。
次に、各層で適度の広がりを持つように、分布の調整を行う手法(Batch Nrmalization)を紹介します。
というのも、ミニバッチ学習などを行った場合、毎回パラメータ更新に使用するデータが異なります。
このデータの分布が異なる場合、損失関数の低下に時間がかかり、学習がうまくいきません。
このように分布が変化することを内部共変量シフト(共変量シフト, Internal Covariance Shift)と呼びます。
Batch Normalizationの仕組み
「各バッチ、各層で平均と分散の正規化実施」これがBatch Normalizationの仕組みとなります。
主な利点は、内部共変量シフトが解消され、学習率を上げても学習できること、過学習を抑制(正則化の必要性が下がる)することです。
入力データは平均0の分散1の分布に収まるように標準化されます。
内部共変量シフト
各層のアクティベーション及び入力分布が変わってしまうことが問題であり、このような状態を指す。
内部共変量シフトが起きている場合、学習を阻害する場合があり、従来はこういったケースに学習率を小さくする/重みの初期値設定を調整する等の対応を実施していた。
過学習への対応
機械学習等の柔軟なモデルを使用する場合は、過学習について気を付ける必要がある。
過学習とは、学習データに合わせこみすぎてしまい、汎化性能を失ってしまうことであり、主な原因として以下があげられる。
- パラメータが多量で柔軟な表現ができる
- 訓練データが少ない
これに対応するやり方として、正則化やDropOut、画像データであればデータの拡張などがあり、その方法を紹介します。
正則化(Weight decay)
モデルの学習は、損失関数の値を小さくすることを目的に実施します。
この手法は、その損失関数の値に「重みを追加する」という手法となります。
このように、重み自体の値が大きくならないように、損失関数にペナルティーを科すという考え方です。
DropOut
過学習を抑制する方法として、Weight decayという方法を説明しました。
Weight decayでもある程度対応は可能ですが、ニューラルネットワークが複雑になると、正則化項を加えたとしても過学習が起きてしまいます。
このようなことに対応する方法として、次にDropOutという手法について説明します。
この方法は、ニューロンをランダムに削減しながら学習する手法です。
データで学習をするたびに、中間層のニューロンをランダムに選んで削除して、実際に学習後にテストを実施する際は削除せずに全てのノードを使用します。
このような手法を使うことで、Baggingのような効果が得られ、過学習が抑制できます。
Baggingを用いたモデルの学習方法をアンサンブル学習と呼び、機械学習ではよく用いられます。
データの拡張
データ数が限られると過学習してしまう危険があるので、データ数を増やすことで過学習を防ぐ手法です。
主に画像データで用いられ、画像を回転/反転/拡大縮小/色の変換などをすることで一つの画像を増やすことが可能になります。
また、似た考え方の別の手法として、半教師あり学習の手法についても説明します。
Early Stopping
その名前の通り、学習を途中で止めるという手法。
正則化が不十分な場合、ミニバッチ学習で学習を数回行っていくうちに、損失関数の値が大きくなるケースがある。
これは、その数値が現れた該当データの前で過学習が起きていることを示しており、このような現象が見られた時に学習を止める手法をEarly Stoppingと呼んでいる。
** パラメータの共有
畳み込みニューラルネットワークで使われる手法であり、フィルタをすることでパラメータ数を削減する手法。
これにより、モデルの表現を制限することで過学習を減らし、副産物として処理負荷も下げることができる。