このアルゴリズムは画像処理において広く使われており、計算負荷を軽減する仕組みが多く導入されています。
目次
Convolutional Neural Network(CNN)の概要
このアルゴリズムでは、畳み込みというフィルタ処理を含んでおり、畳み込みによる出力が次の層の入力として使用されます。このフィルタによって、明るさやエッジなどの特徴、物体を定義する特徴の抽出が可能となります。
畳み込み処理
入力に対して、フィルタを用いて内積計算を行うことに相当し、入力に対してより小さいサイズに畳み込んで出力されます。
図:畳み込みの計算処理
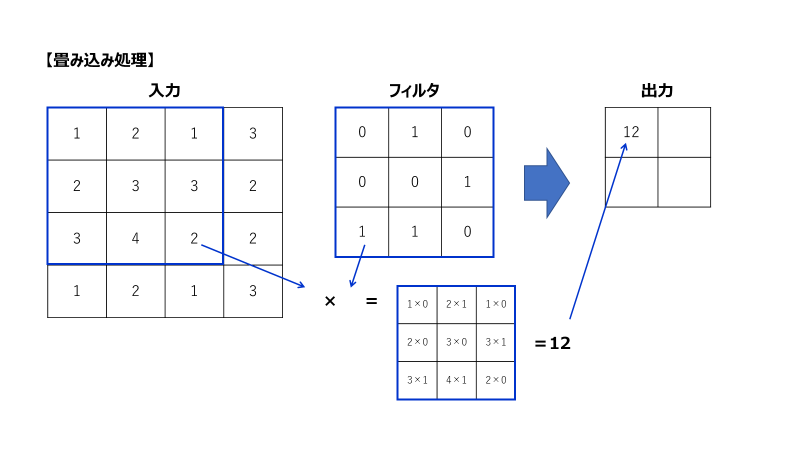
通常のニューラルネットワークでは、入力ごとに重みが異なりますが、畳み込みではフィルタごとに重みが変わるため、重みを使いまわして計算することになります。
特徴抽出・計算を軽くするための処理として利用されるため、出力サイズは入力サイズと比較して小さくなることがポイントです。ただ、小さくなりすぎると計算ができなくなる/層を深くすることができない(その分小さくなるため)などの問題があり、それに対応して、paddingという方法がアルゴリズムに含まれるケースもあります。
padding(zero-padding)
畳み込むときに、入力画像の周りに0埋めの余白をつけるて計算する処理
pooling
入力情報を圧縮処理であり、最大1/2の大きさに入力サイズを圧縮することが可能です。
畳み込みでは、3×3の小さいフィルタを使うケースが多いため局所的な処理しかできないが、Poolingでは広い範囲の情報を含んだまま大きく圧縮することができます。デメリットとしては、入力が小さく圧縮されてしまうため、実施回数に限界があるということです。
Dilated Convolution
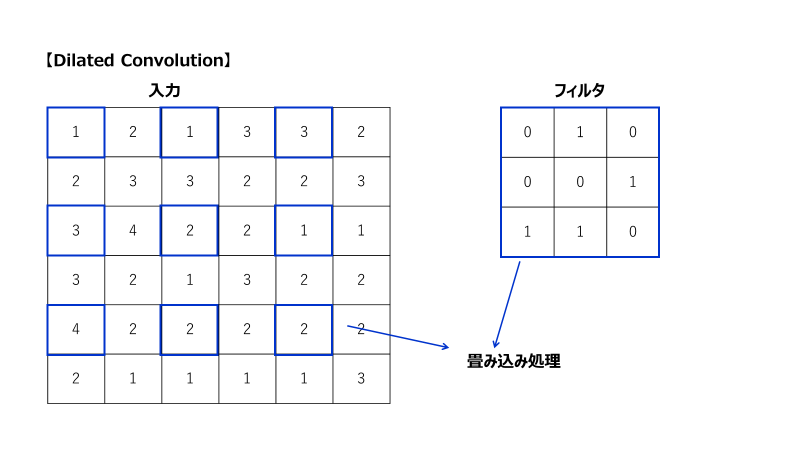
特殊な畳み込み処理であり、通常の畳み込みと比較して広い範囲の情報を含んだまま圧縮することができ、Poolingと比較して出力が小さくなりすぎないという利点があります。
図:Dilated Convolutionの計算処理
UpConvolutin(Deconvolution)
通常の畳み込み処理では、出力の方が入力よりも小さくなるが、この方法は入力よりも出力を大きくする処理になります。
多チャンネル時の処理
多チャンネルとは、フィルタ数が複数になったケースを想定しており、上記の通りの計算方法では、チャンネル数分計算量が倍になり、負荷が非常に重たいです。この計算を効率的に実施する方法として、im2colというテクニックがあります。
※im2colとは:入力やフィルタの2次元領域を、行列の列/行に変換して計算をする手法。GPUは行列計算に長けており、計算方法を変えることで負荷を軽減する。
学習手法
CNNでは、計算量が膨大になるケースが多いため、効率よく学習を実施する必要があり、その手法として以下方法が提案されています。
- Batch Normalization: チャンネル毎にバッチ内の全データを使って平均/分散を求めて正規化する手法
- Instance Normalization: 入力毎に平均/分散を求めて正規化する手法(バッチサイズが1のBatch Normalization)
- Layer Normalization: 全チャンネルにまたがり、平均/分散を求めて正規化する手法で、画像毎に平均/分散を求めることと同じ
- Group Normalization: Layer NormとInstance Normを組み合わせたもので、チャンネルを任意数に分割して、それぞれ平均/分散を求めて正規化する手法
転移学習(Transfer Learning)
別タスクで学習したネットワークを使用して、新しくタスクを学習する手法で、似たものの分類や認識に使ったネットワークを転移学習すると、その学習回数を減らすことができる利点があります。
CNNの代表的なモデル
画像認識で使われるCNNの代表的なモデルとして、以下が提案されています。
- AlexNet: 物体認識に初めて深層学習の概念/畳み込みニューラルネットワークの概念を取り入れたモデル [2012年のILSVRCで優勝したモデル] ※ILSVRCは大規模画像認識の競技会のこと
- VGG16: 畳み込み13層, 全結合3層からなるシンプルなモデル [2014年のILSVRCで提案されたモデル]
- GoogLeNet: モジュールという特定の組み合わせの層を積層させたモデル[2014年のILSVRCで優勝したモデル]
- Residual Networl(ResNet): 現在のCNNのベースとなるモデル。超多層のネットワークであり、超多層での計算を可能にした手法
- DenseNet: ResNetを踏まえて開発されたモデルで、前方の各層からの出力全てが後方の層の入力として使用される手法
- ResNeXt: ResNetのブロック内で入力を分岐させて並列に処理する手法
- MobileNet: スマートフォンにのせれる程度の小さなモデル
- UNet: 画像の出力で使用されるモデル
Object Detection(画像のどこに何があるか)を推定する目的で使用されるモデルとして以下が提案されています。
色々なウィンドウサイズで画面を走査(スライディングウィンドウ)が主流の方法であるが、非常に時間がかかる。
- Regions with CNN features(R-CNN): Selective Searchと呼ばれる領域を絞り込むという機能を含めたモデル
- Fast R-CNN: ROI Poolingと呼ばれる入力を固定サイズに切り分け/プーリングを行うことによって計算量を大幅削減したモデル
- Faster R-CNN: Fast R-CNNを改善したモデルで、途中の演算を共有することによって演算コストを最小化するモデル
- You Only Look Once(YOLO): Faster R-CNNよりも制度は落ちるがリアルタイム計算を可能にしたモデル
- Single Shot MultiBox Detector(SSD): YOLOと似た精度/速度を誇るが、YOLOの弱点であった小さい物体の検出にも強いモデル
まとめ
今回は畳み込み型ニューラルネットワーク CNNに関する概要をまとめました。
計算には大きな負荷がかかり、円滑に計算する手法が多く編み出されているのですね。