誤差逆伝播法
続いては、モデル構築に必要な学習に関する技術を説明します。
目次
ニューラルネットワークの学習
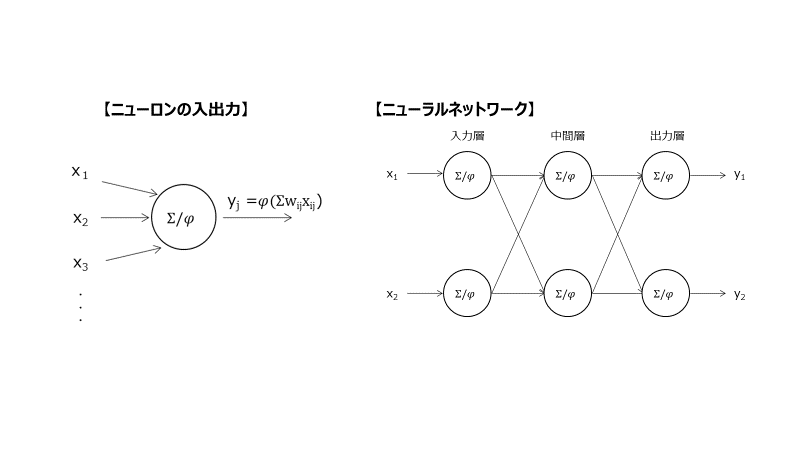
以下画像のようなニューラルネットワークがあったとして、入力x及び出力yの関係は以下の通りです。
この入出力の関係の組み合わせで複雑なモデルが構築できるということでしたね。このモデルをデータにフィットさせる(学習させる)ためには重みwをデータに合わせて変える必要があります。
図:ニューラルネットワーク
勾配降下法
このような関数のパラメータ(係数や重み)を決めるアルゴリズムとして、勾配降下法が使われるので、もう一度紹介します。
勾配降下法は、「モデル関数に対してパラメータ(係数)を更新していって、最適解を目指すこと」が勾配降下法のアルゴリズムです。
ただ、このアルゴリズムをそのままディープラーニングで使用するのは、以下理由からかなり難しい。
- 重みw計算する場合、重みw一つ一つを個別で最適化する必要があり、計算効率が悪い
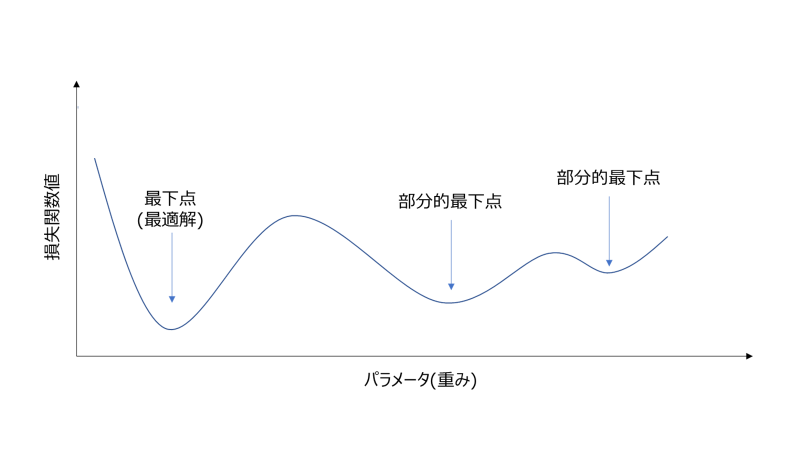
- 凸が複数存在する場合があり、最終的な凸が最適解であるかは分からない(以下図の通り)
図:ディープラーニングの重みと損失関数値の関係
これらの問題をそれぞれ解決するための方法として以下方法があげられる。
1. に対する対策:誤差逆伝播法(Back propagation)
2. に対する対策:確率的勾配降下法(SGD)等
誤差逆伝播法
この方法を使用する前は、「重みwを一つ一つを少し更新して、損失関数の変わり方をチェック(勾配計算)、重みの更新を繰り返す」という方法が用いられていた。つまり偏微分をひたすら計算することになるということであるが、本方法はこの計算を効率的にできるようにした方法だ。
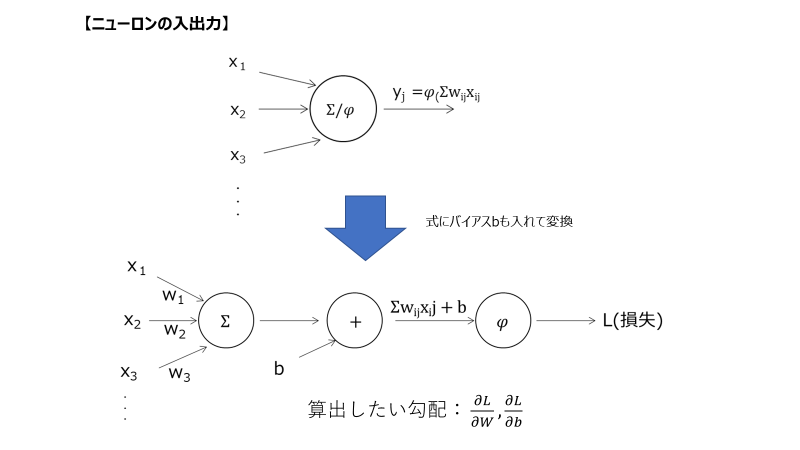
以下図のようなニューロンの計算を考えてみる。
計算したいのは、出力層の損失関数の重み変化に対する勾配。
基本的に足し合わせや掛け算の計算が左から右に流れる構造であり、左の結果が右の結果に影響する。
誤差逆伝播法は、この流れを逆に使用した方法だ。
詳細は以下URLを参照して簡単にまとめると、出力層に入力される値の重みは、以下図のような計算だけしか間に挟まないため、簡単に計算にて求めることができる。
より入力層に近い所の重みについては、上記計算過程で求めた誤差値を一つ前の層の出力値の誤差として扱って計算し、これを連鎖的に入力層側に向かって全ての重みを求める。このような重みを連鎖的に求めることができ、計算負荷を軽減できる方法が誤差逆伝播法だ。
図:ニューロンの計算
qiita.com
勾配消失
前回の記事でも紹介したが、誤差逆伝播法は出力層から入力層に向けて誤差値を伝播させて計算させる方法であるが故、誤差=0となってしまった時点で勾配=0となってしまい、該当層からさらに入力層に近い層の誤差も0となってしまう。
勾配=0となると、重みwの更新が不可能となるため、勾配消失に対する対策が不可欠となる。
勾配消失への対策方法としては、以下方法があげられる。
- ReLu関数等の勾配が消えない活性化関数を使う
- 重みの初期値を設計する
- 入力値の正規化を行う
確率的勾配降下法(Stochastic Gradient Descent :SGD)
SGD の基本的な仕組みは勾配法と同じであるが、パラメータ更新毎にデータをランダムサンプリングするという所が改良ポイント。
ランダムサンプリングするということで、全データを使用しないため、再学習の計算量が低くなるという利点もある。
具体的には以下方法をで計算を行う。
- 損失関数f(x)に対して、学習率ηとxの初期値を定義する。
- データをランダムサンプリングする(ミニバッチ)
- データをもとに勾配(s)計算
- 計算した勾配(s)×η分だけxを変化させる
- 2~4を繰り返す
ミニバッチで学習する方法を"ミニバッチSGD"と、SGDと区別している。
ミニバッチとは
データをすべて使って学習を行うことをバッチ学習と呼び、
データの中からランダムにn個を選び、選んだデータで学習を行うことをミニバッチ学習と呼ぶ。
特に上記にn=1でデータを選ぶ方法はオンライン学習と呼ばれる。
ミニバッチ学習の利点は、バッチ学習と比較して計算リソースが少なく、オンライン学習と比較して重みの更新が安定すること
確率的勾配降下法の改善アルゴリズム
それぞれのアルゴリズムの特徴は、簡単に書くと以下の通り。
- Momentum: SGDのパラメータ更新量を移動平均的な動きに調整
- Nesterovの加速勾配降下法: 確実に損失関数値が減少する方向にパラメータ更新量を調整
- AdaGrad:パラメータ更新量に応じて学習率を調整
- PMSProp:AdaGradアルゴリズムを修正して学習率が低くなりすぎないように調整
- Adam: MomentumとPMSPropを組み合わせたアルゴリズム
Momentum
過去の更新方向から、更新量を調整するテクニック
Momentum(慣性)と言われるように、重みが更新されている方向に更新量が上澄みされる。
重み更新の動きが、移動平均をかけたような感じになる。
Momentumを含めたSGDアルゴリズム
γは、前回の勾配値の重みであり、パラメータ更新量mは通常のSGDから移動平均をかけたような動きを示す。
Nesterovの加速勾配降下法
Nesterov Accelerated Gradient :NAGと呼ばれ、Momentumを改善したアルゴリズム。
パラメータ更新量の方向が正しい方向を向いているかを確かめた上でパラメータを更新するという考え方。
Momentumだけでパラメータ更新した後の勾配を確認して、パラメータを更新する。
先にMomentumの項で重みを変更させて勾配を計算している。
上記の通り、アルゴリズムを分けて説明したが、すべて含まれたものをSGDとして扱うことも多い。
それぞれの処理の動きをアニメーションで示したページがあったので、紹介する。
qiita.com
AdaGrad
SGDでは学習率ηは常に固定であるが、この調整を加えたアルゴリズム。
更新回数に応じて学習率を変更する。基本的には、学習回数が多い場合は学習率を下げる。
パラメータeは、0除算を防ぐためのきわめて小さい値です。
まとめ
今回は逆誤差伝播法についてまとめました。
各アルゴリズムの動きをコードで確認している最中なので、それが完成したら公開しようと思います。