LLMの活用事例を考える中で、LLMにアイデア出しを手助けしてもらえたら嬉しいなぁと思いました!
ただ、「○○の課題解決に関するアイデアを出して」というと、そこそこは出ますが、結構考え方が1方向だったり、結構同じアイデアばかりだったりして、ちょっと微妙だな・・・と。
実際自分で考えるときも、まずは1方向で考えることが多く、「こういう側面では?」という考える上での前提が変わるとアイデアが出たりするので、そういったフレームワークも利用したアイデア出しをLLMにやらせてみようと考えました。
そこで、今回はSCAMPER法というフレームワークに従って、アイデア検討ができるアプリを作ってみました。
アプリデプロイの部分で少し手こずったので、、その記録の保存もかねて共有します。
stockmark.co.jp
↓作ったアプリはこれ(24年4月中ぐらいは動かすかも)
https://gcp-gradio-gemini-scamper-szqddm3h4a-dt.a.run.app
目次
構成について
python, LLM(Gemini) APIの利用にはLangChainライブラリ、アプリ部分はGradioライブラリ、実装はGCP CloudRunを使用しています。
基本的な構成は以下ブログで記載と大きな差はありません。
dango-study.hatenablog.jp
構成詳細
│─ Dockerfile │─ requirements.txt └─ src/ └─ main.py (WEBアプリのコード)
コード詳細
メインの処理
使わなくてもよいのですが、Gemini APIへのアクセスなどLLM関連の取り扱いにはLangChainのライブラリを使っています。
本当は、Gemini APIへのアクセスをasyncを用いて並列処理でやりたかったのですが・・・うまくできていません。
修正時間がかかりそうだったので中途半端な状態で残っています。
main(メイン)処理のコード
# -*- coding: utf-8 -*-
import os
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.prompts import (
ChatPromptTemplate,
)
import gradio as gr
GOOGLE_API_KEY="ここにAPIkeyを入れる"
llm = ChatGoogleGenerativeAI(
model="gemini-pro",
temperature=0.9,
google_api_key=GOOGLE_API_KEY,
convert_system_message_to_human=True
)
async def use_llm(role, sentences):
#await asyncio.sleep(delay)
# プロンプトのテンプレート文章を定義
template = """
{role}: にのっとった具体例を複数出力してください。
ユーザーからの依頼: {sentences}
"""
# テンプレート文章にあるチェック対象の単語を変数化
prompt = ChatPromptTemplate.from_messages([
("system", """あなたは開発者のアイデア出しをアシストを担当します。
アイデアの発想にはいくつかの典型的なパターンがあり、限られた時間で多くのアイデアを創出するのに効果的なフレームワークSCAMPER法を用います。
Scamper法はS: substitute, C:combine, A:adapt, M:modify, P: put to other uses, E:eliminate, R:reverse and rearrangeで構成されています。
Scamper法は、それぞれの質問に応じて、意見を出していく。あなたは、userからの依頼内容について、Scamper法の役割に応じた質問を受けた場合の応答を複数箇条書きで出力ください。
[S: substitute]:#何か別のものに置き換えができないかを探る質問だ#プロセスや手順を置き換えるとどうなるか。成分や材料を置き換えるとどうなるか。五感(音・触感・色・香り・味)に関するものを置き換えるとどうなるか。場所、時間、人、方法を置き換えるとどうなるか。
[C: combine]:#2つ以上のものを組み合わせて新しいアイデアを生み出す質問だ#まったく異なる2つの製品を組み合わせる。目的や方法を組み合わせる。一部の機能を統合する。
[A: adapt]:#もともとあるアイデアを応用することで、新しいアイデアを着想する質問だ。#他の業界のアイデアを当てはめるとどうなるか。過去の成功事例を応用できないか。他にどのような使い方ができるか。
[M: modify]: #製品やサービスを修正・変更することで、新しいアイデアの発想につなげる質問だ。#重さを変えてみたらどうなるか。機能を弱く/強くしたらどうなるか。製品を短く/長くしたらどうなるか。製品を小さく/大きくしたらどうなるか。動作を遅く/早くしたらどうなるか
[P: put to other uses]:#技術や素材などをこれまでとは別の使い方や目的で使用することができないかを探る質問だ。#他にどのような使い道が考えられるか。業界を変えたらどうなるか。ターゲットを変えたらどうなるか。
[E: eliminate]:#プロセスや機能を排除、削除することで新しいアイデアを出す質問だ。#機能やサービスを最小限にできないか。プロセスや過程を簡略化できないか。見た目やデザインをシンプルにできないか。
[R: reverse and rerrange]#逆にしたり、並べ替えたりして、再構成をすることで新しい発想を生み出す質問だ。#プロセスや順序を入れ替えてみる。原因と結果を逆にしてみる。表面と裏面を入れ替えてみる。弱みを強みに転換してみる。
[attention1]出力結果は、検討した結果のみに限定し、結果に関係ないことは出力しないでください。
[attention2]質問意図が分からない場合は、その旨を伝え、質問例を出力ください。質問例「タイヤに欲しい機能は」などの質問
"""),
("user", template)
])
chain = prompt | llm
result = chain.invoke({"sentences": sentences, "role": role})
return result.content
async def main(user_query):
substitute = await use_llm("S: substitute" , user_query)
combine = await use_llm("C: combine" , user_query)
adapt = await use_llm("A: adapt" , user_query)
modify = await use_llm("M: modify" , user_query)
put = await use_llm("P: put to other uses" , user_query)
eliminate = await use_llm("E: eliminate" , user_query)
reverse = await use_llm("R: reverse and rerrange" , user_query)
return substitute, combine, adapt, modify, put, eliminate, reverse
with gr.Blocks(theme=gr.themes.Soft()) as app:
gr.Markdown("# SCAMPER アイデア創出アプリ")
gr.Markdown("提供された入力に基づいて、SCAMPER手法を用いたアイデアを生成します。")
gr.Markdown("例:タイヤの空気が抜けないようにする。")
with gr.Row():
user_query = gr.Textbox(label="あなたのアイデアを入力してください")
with gr.Row():
button = gr.Button("生成")
with gr.Row():
with gr.Column():
gr.Markdown("# <span style='color: blue;'>S: Substitute")
gr.Markdown("### 何か別のものに置き換えができないかを探る")
substitute_output = gr.Textbox(label="代替案", lines=9)
with gr.Column():
gr.Markdown("# <span style='color: blue;'>C: Combine")
gr.Markdown("### 2つ以上のものを組み合わせて新しいアイデアを生み出す")
combine_output = gr.Textbox(label="組み合わせ案", lines=9)
with gr.Column():
gr.Markdown("# <span style='color: blue;'>A: Adapt")
gr.Markdown("### 応用することで、新しいアイデアを着想する")
adapt_output = gr.Textbox(label="適応案", lines=9)
with gr.Column():
gr.Markdown("# <span style='color: blue;'>M: Modify")
gr.Markdown("### 修正・変更することで、新しいアイデアを着想する")
modify_output = gr.Textbox(label="変更案", lines=9)
with gr.Row():
with gr.Column():
gr.Markdown("# <span style='color: blue;'>P: Put to other uses")
gr.Markdown("### 別の使い方や目的で使用することができないかを探る")
put_output = gr.Textbox(label="他の用途案", lines=9)
with gr.Column():
gr.Markdown("# <span style='color: blue;'>E: Eliminate")
gr.Markdown("### プロセスや機能を排除、削除することで新しいアイデアを出す")
eliminate_output = gr.Textbox(label="削除案", lines=9)
with gr.Column():
gr.Markdown("# <span style='color: blue;'>R: Reverse,Rearrange")
gr.Markdown("### 逆にしたり、並べ替えて、再構成をすることで新しい発想を生み出す")
reverse_output = gr.Textbox(label="逆転案", lines=9)
button.click(
main,
inputs=[user_query],
outputs=[substitute_output, combine_output, adapt_output, modify_output, put_output, eliminate_output, reverse_output]
)
if __name__ == "__main__":
port = int(os.getenv("PORT", "7860"))
#app.launch(server_port=port)
app.launch(server_name="0.0.0.0", server_port=port)
Dockerファイル
Dockerfileは以下のような設定です
FROM python:3.11.1 WORKDIR /app RUN python -m ensurepip RUN python -m pip install --upgrade pip COPY requirements.txt ./requirements.txt RUN pip install -r requirements.txt COPY . . EXPOSE 7860 CMD python src/main.py
デプロイ
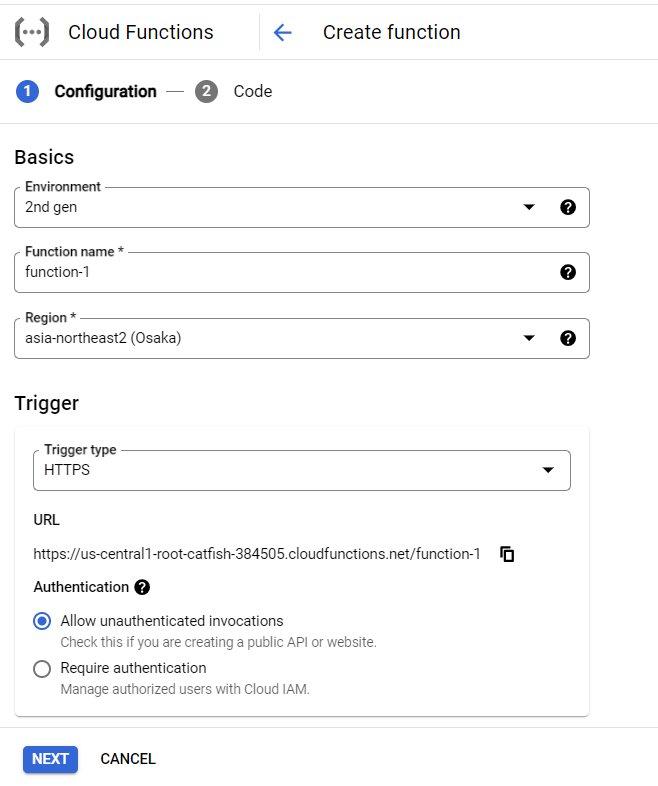
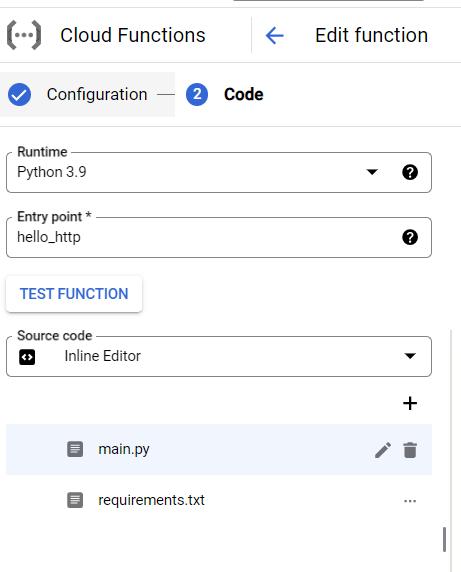
作成したソースやファイルたちは、Githubにあげた後、
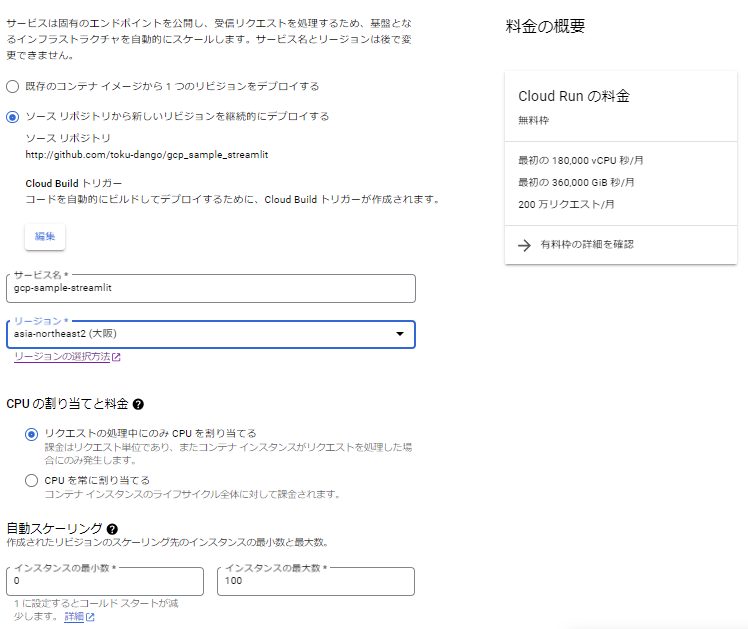
Cloud Runのページで、ソースリポジトリからのデプロイを選択、Githubの対象リポジトリを選択します。
↓以下画像は、デプロイ後に参照した設定。初期デプロイ時は、コンテナポートを$PORT設定にしている。Gradioは7860がデフォルトポートになるようなので、この設定になっている。

今回の作業は以下のページも参考にして対応しています。(感謝)
blog.g-gen.co.jp
これでデプロイは完了になります。
デプロイで困ったこと
main.pyの以下コードについて、app.launchでのサーバーネームの設定を"0.0.0.0"にしないとサーバー起動できないようで、エラーで止まりました。
サーバーネーム=0.0.0.0はワイルドカードのような感じで、すべてのネットワーク・インターフェース表し、アクセスできるようになるようです。
if __name__ == "__main__":
port = int(os.getenv("PORT", "7860"))
#app.launch(server_port=port)
app.launch(server_name="0.0.0.0", server_port=port)
動作確認
デプロイ後に吐き出されるURLにアクセスをすると、Gradioのアプリが無事動いていることを確認しました。

試しに「ゴミ出しを忘れないようにするには」と入力して出力を見てみたのですが、
・ゴミ出しアプリやスマートゴミ箱を使用して自動的にアラートを出す
・ゴミ出しアプリとカレンダーアプリを組み合わせる。
・ゴミ出しを忘れないようにアラームを設定できる、ゴミ箱を開発する。
・ゴミを捨てるたびにポイントが貯まり、景品と交換できるサービスを導入する。
・ゴミ捨てを社会的なイベントに変え、近所の人が一緒にゴミ捨てをするような企画を実施する。
→結構色々出してくれて面白いなぁと思いました。特にポイントがたまって景品と交換できるサービスは、ぱっと浮かばないなぁと感心しました。