LangChainは、Large Language Models(LLM)を使ったアプリケーション開発を容易にするためのフレームワークです。LLMと会話をする際に会話履歴の保管しておく機能や、Agentと呼ばれる機能等、自身で色々と書かないと実現できなかったことが簡単にできる所がとても良いです。(詳細以下)
www.langchain.com
今回は、このLangChainとGoogle Gemini API(今は無料で使えるので)を用いて簡単なチャットアプリとpdfを読み込んで、そのpdfの内容に応じて答えを出してくれるアプリを作ったので、その記録を残します。
目次
構成について
LLMとの会話はpython, LangChainライブラリ、アプリ部分はStreamlitライブラリ、実装はGCP CloudRunを使用しています。
基本的な構成は以下ブログで記載と差が無く、app.pyのコードのみ変更します。
dango-study.hatenablog.jp
構成詳細
│─ Dockerfile │─ requirements.txt └─ src/ └─ app.py (WEBアプリのコード)
コード詳細
簡単なチャットアプリ
LangChainのConversationChainの機能を使用しています。
以下はapp.pyのコードの抜粋です。
import streamlit as st
from streamlit_lottie import st_lottie
from langchain.chat_models import ChatVertexAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import AIMessage, HumanMessage, SystemMessage
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.cache import InMemoryCache
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
import requests
from dotenv import load_dotenv
import os
GOOGLE_API_KEY = "自身で取得したAPI KEYを入力"
langchainllm_cache = InMemoryCache()
llm = ChatGoogleGenerativeAI(model="gemini-pro",
temperature=0.3, convert_system_message_to_human=True,google_api_key=GOOGLE_API_KEY)
def get_state():
if "state" not in st.session_state:
st.session_state.state = {"memory": ConversationBufferMemory(return_messages=True, k=5)}
return st.session_state.state
state = get_state()
print(state)
chain = ConversationChain(
llm=llm,
memory=state['memory']
)
def load_lottieurl(url:str):
r = requests.get(url)
url_json = dict()
if r.status_code == 200:
url_json = r.json()
return url_json
else:
None
load_bot = load_lottieurl("https://lottie.host/dffb1e31-78af-4548-9e7c-30fd1cbbb704/lUvwHha1IZ.json")
col1,col2 = st.columns(2)
with col1:
st.markdown('')
st.markdown('')
st.title(":violet[AI Bot]")
with col2:
st_lottie(load_bot,height=200,width=200,speed=1,loop=True,quality='high',key='bot')
# Set a default model
if "vertexai_model" not in st.session_state:
st.session_state["vertexai_model"] = "chat-bison"
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Accept user input
if human := st.chat_input("Please ask assistant"):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": human})
# Display user message in chat message container
with st.chat_message("user"):
st.markdown(human)
# Display assistant response in chat message container
with st.chat_message("assistant"):
message_placeholder = st.empty()
with st.spinner("Processing..."):
#full_response = gen_response(human)
full_response = chain(human)
try :
message_placeholder.markdown(full_response["response"])
st.session_state.messages.append({"role": "assistant", "content": full_response["response"]})
print(full_response)
#print()
except:
print("error")
実行結果
デプロイ方法は以下の記載と同じなので、ここでは割愛します。
WEBアプリをクラウドでデプロイ(Cloud Run + Streamlit or Flask) - まるっとワーク
実行結果として、会話が正常に行え、その記録もしっかり残せています。
streamlitは、変数保持に対応が必要なので、会話履歴に対しては保持するための対応をしています。
【Streamlit】Session Stateで変数の値を保持する方法 #Python - Qiita

pdfの内容に応じて答えを出してくれるアプリ
同様にLangChainのConversationChainの機能を使用しています。
ただし、特定の命令(プロンプト)を与えています。
以下はapp.pyのコードの抜粋です。
構成詳細
import streamlit as st
from streamlit_lottie import st_lottie
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain import PromptTemplate
from langchain.cache import InMemoryCache
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain.text_splitter import CharacterTextSplitter
from langchain.agents import AgentType, AgentExecutor, ZeroShotAgent, Tool, initialize_agent, load_tools
import requests
from langchain.tools import WriteFileTool
import PyPDF2
import io
GOOGLE_API_KEY = "自身で取得したAPI KEYを入力"
langchainllm_cache = InMemoryCache()
llm = ChatGoogleGenerativeAI(model="gemini-pro",
temperature=0.3, convert_system_message_to_human=True,google_api_key=GOOGLE_API_KEY)
def get_state():
if "state" not in st.session_state:
st.session_state.state = {"memory": ConversationBufferMemory(return_messages=True, k=5)}
st.session_state.state["count"] = 0
return st.session_state.state
state = get_state()
print(state)
tools = load_tools(
[],
llm=llm
)
tools.append(WriteFileTool())
chain = ConversationChain(
llm=llm,
memory=state['memory']
)
if state["count"] >= 0:
prompt = PromptTemplate(
input_variables=["system_input", "document_input", "user_input"],
template="""System Prompt Here: {system_input}
Document Input: {document_input}
User Prompt: {user_input}"""
)
else:
prompt = PromptTemplate(
input_variables=["user_input"],
template="""
User Prompt: {user_input}"""
)
print("Not First")
system_input = """####Document Input#####の内容を踏まえて、####User Prompt####の命令に従って回答してください。これを厳守してください"""
agent = initialize_agent(
tools,
llm,
memory=state["memory"],
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
def load_lottieurl(url:str):
r = requests.get(url)
url_json = dict()
if r.status_code == 200:
url_json = r.json()
return url_json
else:
None
def get_pdf_text():
st.markdown('Managed by: <a href="https://dango-study.hatenablog.jp/">Kazuma Tokuda</a>',unsafe_allow_html=True)
st.markdown('')
st.title(":violet[Document AI Search]")
uploaded_file = st.file_uploader(
label='Upload your PDF here😇',
type='pdf'
)
if uploaded_file:
# ファイルをメモリに読み込む
file_buffer = io.BytesIO(uploaded_file.getvalue())
# PyPDF2を使用してPDFを読み込む
pdf_reader = PyPDF2.PdfReader(file_buffer)
text = ''
for page in range(len(pdf_reader.pages)):
text += pdf_reader.pages[page].extract_text() + '\n'
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 100,
chunk_overlap = 0,
length_function = len,
)
text_list = text_splitter.split_text(text)
document_list = text_splitter.create_documents([text])
st.session_state.pdf_text = text_list
st.write(text_list)
def page_ask_my_pdf():
load_bot = load_lottieurl("https://lottie.host/dffb1e31-78af-4548-9e7c-30fd1cbbb704/lUvwHha1IZ.json")
col1,col2 = st.columns(2)
with col1:
st.markdown('')
st.title(":violet[Document AI Search]")
if "pdf_text" in st.session_state:
pdf_text = st.session_state.pdf_text
# PDFテキストを使用して何か処理を行う
# 例: st.write(pdf_text)
with col2:
st_lottie(load_bot,height=200,width=200,speed=1,loop=True,quality='high',key='bot')
# Set a default model
if "vertexai_model" not in st.session_state:
st.session_state["vertexai_model"] = "chat-bison"
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Accept user input
if human := st.chat_input("Please ask assistant"):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": human})
# Display user message in chat message container
with st.chat_message("user"):
st.markdown(human)
# Display assistant response in chat message container
with st.chat_message("assistant"):
message_placeholder = st.empty()
with st.spinner("Processing..."):
custom_prompt = prompt.format(system_input=system_input, document_input= pdf_text,user_input=human)
print(custom_prompt)
print(state["memory"])
full_response = agent(custom_prompt)
state["count"] += 1
try :
#print("full_response", full_response)
message_placeholder.markdown(full_response["output"])
st.session_state.messages.append({"role": "assistant", "content": full_response["output"]})
#print("st.session_state", st.session_state)
except Exception as e:
st.error(f"An error occurred: {str(e)}")
print(e)
else:
st.markdown("まずpdfファイルを読み込んでください")
def main():
selection = st.sidebar.radio("Go to", ["PDF Upload", "Ask My PDF(s)"])
if selection == "PDF Upload":
get_pdf_text()
elif selection == "Ask My PDF(s)":
page_ask_my_pdf()
if __name__ == '__main__':
main()
実行結果
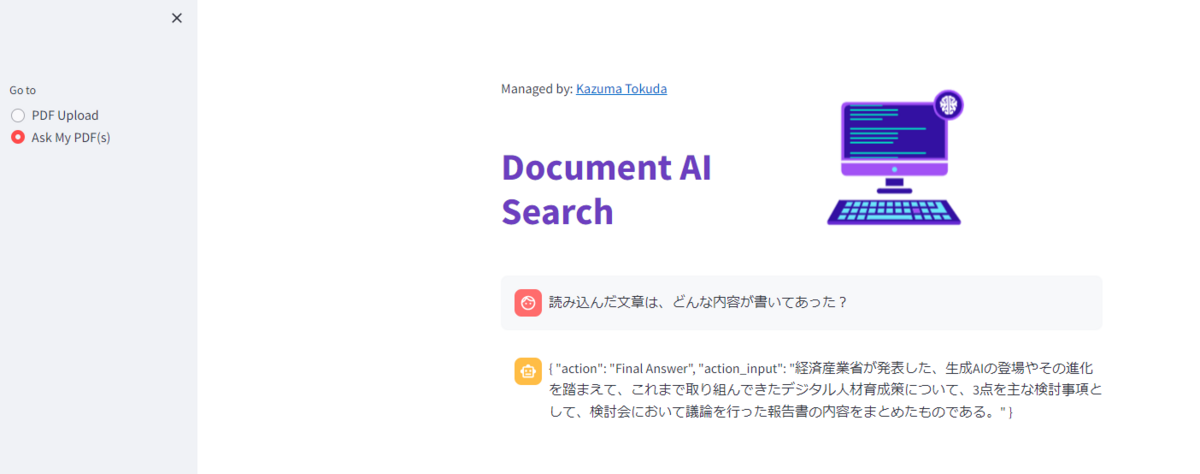
pdfを読み込むページと会話をするページを分けています。
pdfを読み込むと読み込んだ結果が表示されます。

会話をするページでは、聞いた内容及びpdfの内容も踏まえて回答してくれています。
ただ、まだ制御が怪しくきれいに出すことができていません・・
また、プロンプトインジェクションにも弱く、なかなか難しいですね・・