ニューラルネットワークについて①
今回は、ニューラルネットワークについて説明していきたいと思います。
目次
ニューラルネットワークとは
人工ニューロンを多く組み合わせたものを「ニューラルネットワーク(NN)」と呼びます。
ニューラルネットワークのうち、一方通行であるものを「Feed-forward NN」、多層(4層)以上のものを「Deep Learning NN」と呼びます。
前回の記事でも書きましたが、ニューロン単体だけでは線形的な単純な表現しかできません。
ただ、複数を重ね合わせることで複雑な表現ができるようになり、様々なデータ上の現象に対応したモデルが作れるようになるということですね。
これはまだ言いすぎですが・・
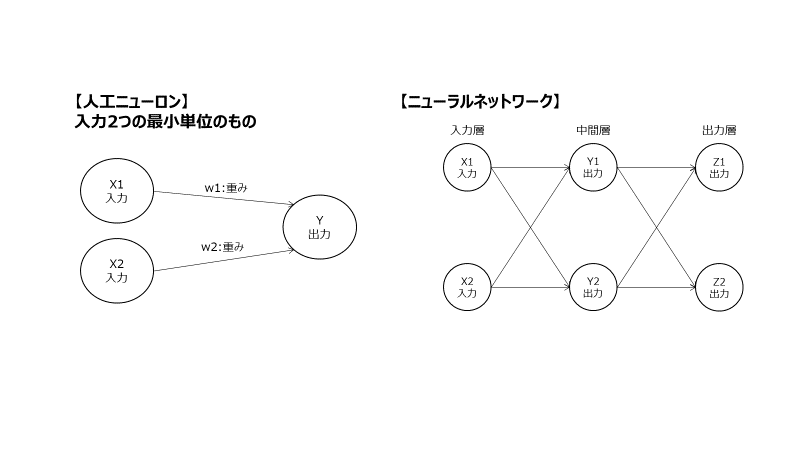
ニューラルネットワークの例
ニューラルネットワークの例を以下画像に示します。
一番左の列を「入力層」、一番右列を「出力層」、2つに挟まれた層を「中間層(隠れ層)」と呼びます。
図:ニューラルネットワーク例
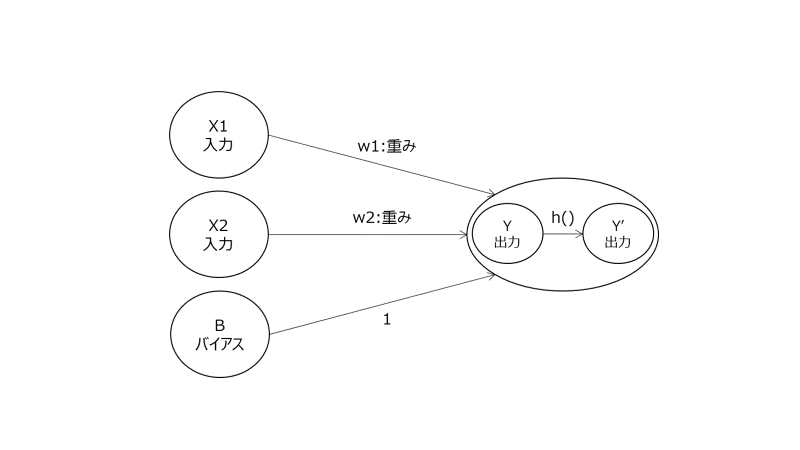
活性化関数の導入
ニューラルネットワークは、人工ニューロンの重ね合わせであり、それによって複雑な表現ができるという話をしました。
ただ、線形的な表現の組み合わせでは非線形なモデルは構築できません。
非線形的なより複雑な現象に対応するための方法として、活性化関数の導入があります。
図:人工ニューロンの例
活性化関数の種類(Activation Function)
活性化関数によって非線形的な表現が可能になるということでしたが、どういった関数なのかをまとめます。
ニューラルネットワークは人工ニューロンの重ね合わせであり、人工ニューロンそれぞれに活性化関数が導入されます。
ニューラルネットワーク上の人工ニューロンの位置によっても活性化関数の役割が変わってくるので、それぞれに対して設計必要です。
ただ、一般的には以下性質を持つような関数が望ましいものとして使われます。
- 微分可能: 後述の重みの計算を実施する為に必須な性質
- 非線形:非線形性を持っていないと意味がないので、必須な性質
- 学習が速い
- 出力値がある範囲に絞られる:出力層などで、出力値を0~1にしたいなど出力値に指定がある時に必要な性質
代表的な活性化関数
【出力層で多く使われる】
- 線形関数(恒等関数):入力信号の総和がそのままほしい場合に使用。非線形な表現が求められている場合には使いません。
- シグモイド関数:出力がベルヌーイ分布(0~1)の時に使用。出力層で使用する場合が多い。
- ソフトマックス関数:マルチヌーイ分布について使用される。全種類のカテゴリに属する確率算出で使用され、全確率を合計すると1になるような出力を持つ。
【中間層で多く使われる】
- ReLu関数:非線形性が強く、後述する勾配が消えないという効果を持つ。
- シグモイド関数:上記記載
- ハイパボリックタンジェント:シグモイド関数では、0~1の範囲の出力となるが、こちらは-1~1の出力範囲を持つ。
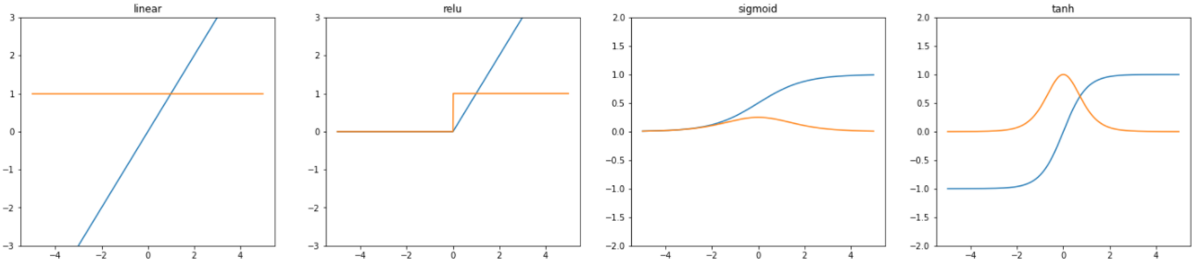
図:代表的な活性化関数のグラフ(左から順に線形関数、ReLu関数、シグモイド関数、ハイパボリックタンジェント)
オレンジ:活性化関数を微分したもの(導関数)
活性化関数選びの注意点
ニューラルネットワークでは、出力値(予測値)と実際の値の差分である誤差を最小化するために、重みの更新を行う学習を行います。
具体的には、勾配降下法、誤差逆伝播法を使って計算される勾配値を基に重みを更新します。
ただ、この勾配値は活性化関数に依存し、活性化関数の選び方によっては勾配=0となるケースが多くなる場合があります。
勾配=0となると、パラメータは更新されなくなり学習が進まなくなるため、このような勾配消失の課題に対して考慮する必要があります。
具体的な計算については、誤差逆伝播法の説明の際にまとめようと思いますが、
人工ニューロンの出力値は活性化関数を通して計算されるため、活性化関数の導関数を用いて簡単に考えることが可能です。
先程のグラフ オレンジ(導関数)のプロットの縦軸が勾配になります。
例えば線形関数では、どの値でも1をしてしており、勾配は常に存在します。
ただ、シグモイド関数では、最大値が0.25、ただしほとんど領域が0に近い値をとります。
逆伝播計算では、この勾配を出力層から入力層方向に乗算していって、重みを更新するという計算をする為、
シグモイド関数のような活性化関数を中間層で多用すると、あっという間に勾配が0に近づいてしまいます。
これが勾配消失です。なので、シグモイド関数、ハイパボリックタンジェントなどの関数を中間層で使用することは好ましくないといえます。
勾配降下法
参考までに勾配降下法を説明します。
先程、「ニューラルネットワークでは、出力値(予測値)と実際の値の差分の誤差を最小にするために、重みの更新を行う」と説明しました。
ニューラルネットワークだけではなく、「モデル関数に対してパラメータ(係数)を更新していって、最適解を目指すこと」が勾配降下法のアルゴリズムです。
「最適解が何か」を説明する為に、説明変数が1つの関数を例とします。
つまり、
※上記のような結果の良し悪しの評価に使う式をコスト関数、損失関数と呼びます。
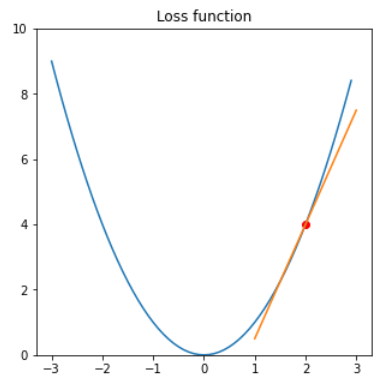
勾配降下法は、損失関数における現在の位置から勾配の方向に任意の距離だけ進むアルゴリズムになります。
つまり、以下図で見ると損失関数=0になるところにパラメータを更新したい為、現在値(赤点)で微分、微分値の逆方向にパラメータを動かすという方法です。
図:損失関数と勾配計算
変数が複数の場合は偏微分を行い、それぞれの変数に対する微分値(勾配)を求めることで同様に計算が可能です。
「微分によって勾配を求め、パラメータ更新のベクトル方向を決める。パラメータを更新する」このイメージがつかめればよいと思います。
まとめ
今回はニューラルネットワークについて、まとめました。
すべて書ききれなかったので、続きは次にするとして、今回の記事で活性化関数の設計、勾配降下法について理解の助けとなれたら幸いです。