ChatGPTを使った自動レシピジェネレーター サービスの作成方法を紹介します。
このサービスは、食材を入力するだけでレシピを考案し、提供するサービスです。システムの構成には、ChatGPT API + AWSサービス(Lambda + API Gateway)とLINEを使用し、連携させて、構築しています。
正直言うと、AWSサービスとLINEの連携さえ済めば、ChatGPT APIを使ってメッセージを返して貰う所だけを追加するだけなので、そこまでハードルは高くない。
それ以上に重要なことは、望んだ答えを出すような命令方法(プロンプトの設計)とアウトプットのさせ方だなと感じた。
以下先人の皆様の情報を利用して作成しており、尊敬を込めてご紹介します。
[ChatGPT]OpenAI APIでGPT-3.5系のモデル「gpt-3.5-turbo」と「text-davinci-003」をLambdaで試してみた | DevelopersIO
[ChatGPT API][AWSサーバーレス]ChatGPT APIであなたとの会話・文脈を覚えてくれるLINEボットを作る方法まとめ | DevelopersIO
目次
実装
LINE Message APIを使うための環境を整える/AWS の環境を整える+LINEと連携する[省略:別ページで紹介]
これらの手順は過去のブログで説明をしているので、そちらをご参照ください。
AWS Lambda環境では、openaiモジュールを使用するので、AWS Lambdaのレイヤーにはopenaiモジュールを入れる必要があります。
dango-study.hatenablog.jp
AWS Lambdaでコード実行(動作確認)
コード作成
Lambda関数では、以下コードを作成/実行する。
openai.ChatCompletion.createの戻り値は、class 'openai.openai_object.OpenAIObject'であり、戻り値の読み込みには注意が必要。
以下の通り対応することで、辞書形式に変更ができ、扱いやすくなる。
dictionary = openai_object.__dict__#辞書形式に変更
コード詳細↓
import json
import urllib.request
import os
import openai
from linebot import LineBotApi
from linebot.models import TextSendMessage
from datetime import datetime
#######APIキーを取得
openai.api_key = os.environ["Openai_ACCESS_TOKEN"] #自身で設定した環境変数の値に変更
# 環境変数からLINE Botのチャネルアクセストークンを取得
LINE_CHANNEL_ACCESS_TOKEN = os.environ['LINE_CHANNEL_ACCESS_TOKEN'] #自身で設定した環境変数の値に変更
# チャネルアクセストークンを使用して、LINE BotのAPIインスタンスを作成
LINE_BOT_API = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN)
########説明
#LINEで入力されたテキストは ['events’][0]['message’]['text’] に入っています。
#また、受信したメッセージに対してリプライを行うには、replyTokenの値を使用します。
# ログ出力関数
def logging(errorLv, lambdaName, errorMsg):
loggingDateStr=(datetime.now()).strftime('%Y/%m/%d %H:%M:%S')
print(loggingDateStr + " " + lambdaName + " [" + errorLv + "] " + errorMsg)
return
def make_prompt(input):
prompt_h = "{Input}を用いて、{Goal}を達成するための料理のレシピを{提案フォーマット}で回答する。\n"\
"{Input}が食材名の場合は、その内容に応じてランダムに選んだ料理名を{Goal}とする。\n"\
"{Input}が料理名の場合は、料理名を{Goal}とする。\n"\
"{Input}に食材名や料理名以外が含まれる場合、料理のレシピ提案をせず、{代替案フォーマット}で回答する。\n"\
"{提案フォーマット}と{代替案フォーマット}のどちらか一方のみで回答することを厳格に守る。\n"
prompt_i = "{Input} = "
prompt_c = "/n{提案フォーマット}\n"\
"【提案する料理】\n"\
"{料理名}\n"\
"【材料】\n"\
"{食材1}:{分量1}\n"\
"【手順】\n"\
"{手順1}\n"\
"{代替案フォーマット}\n"\
"{Input}には対応するレシピを提案できません。別の食材や料理名を入力してください。"
prompt_all = prompt_h+prompt_i+input+prompt_c
return prompt_all
def use_chatgpt(input):
prompt_ = make_prompt(input)
#モデルを指定
model_engine = "gpt-3.5-turbo"
# 推論
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt_}
])
# 回答
print(response.__dict__)
#出力結果は、class 'openai.openai_object.OpenAIObject'であり、これを辞書形式で見込む
answer = response.__dict__["_previous"]["choices"][0]["message"]["content"]
logging("info", answer, "回答出力")
return answer
def lambda_handler(event, context):
logging("info", context.function_name, "実行開始")
if json.loads(event["body"])["events"][0]["type"] == "message":
if json.loads(event["body"])["events"][0]["message"]["type"] == "text":
reply_token = json.loads(event["body"])["events"][0]['replyToken']# リプライ用トークン
message_text = json.loads(event["body"])["events"][0]["message"]["text"]# 受信メッセージ
#chatgptにpromptを送る
logging("info", context.function_name, "use_api")
response_text = use_chatgpt(message_text)
print("response",response_text)
# メッセージを返信
LINE_BOT_API.reply_message(reply_token, TextSendMessage(text=response_text))
return {'statusCode': 200, 'body': json.dumps('Reply ended normally.')}
コード(関数)解説
- def logging(errorLv, lambdaName, errorMsg):
AWS CloudWatch Logsにログを残すための関数。特になくても処理には問題ない
- def make_prompt(input):
ChatGPTに渡すプロンプトを作成する関数。引数inputにはLINEで受け付けた文字が入り、その文字を加えてプロンプトが完成し、戻り値returnとして返す
- def use_chatgpt(input):
ChatGPT APIに値を渡し、結果をもらうためのメソッド
- def lambda_handler(event, context):
イベントを処理するメソッドで、関数が呼び出される(LINEでメッセージを受け付けたタイミングでAWS API Gatewayに呼び出される)と、このLambda_habdlerメソッドが実行される。LINEからのメッセージは、引数eventに含まれる。
実行結果
LINEでメッセージを送った際の実行結果は以下の通り、意図通り、レシピを返してくれます。
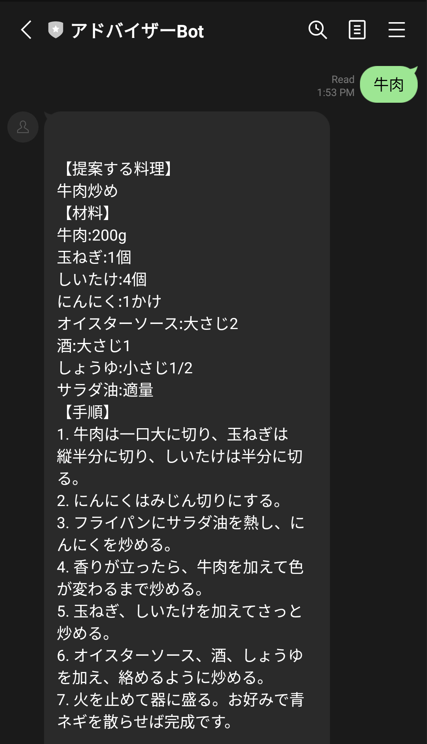
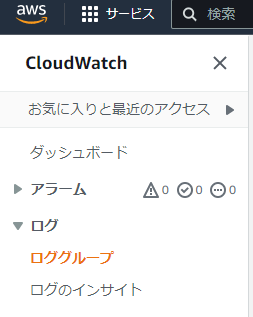
エラーが出た時の対処法
Amazon CloudWatchの、ログ->ロググループを選び、対象となるLambda関数を選択すると、実行毎のログを確認できます。
これで、LINEにメッセージを送った後、の結果を追うことができ、エラー処理も対応できるので、便利です。
まとめ
今回は、AWSサービスとLINEを連携させ、ChatGPTを組み合わせた自動レシピジェネレーター サービスの作成方法を紹介しました。
このサービスは、食材を入力するだけで簡単に美味しい料理のアイデアを提供してくれます。ChatGPTは、豊富なレシピデータと自然言語処理アルゴリズムを組み合わせ、リアルな文章でレシピを生成することができます。実際に試してみたところ、多くの料理のアイデアを得ることができたため、日々の料理のバリエーションを増やすことができました。自動レシピジェネレーターを使うことで、手軽に料理のアイデアを得られるため、忙しい人や初心者の方にもおすすめです。
こういったサービスがどんどん世に出ていくのだなぁと思い、ChatGPTなどのAI技術の発展に今後も期待です!



















