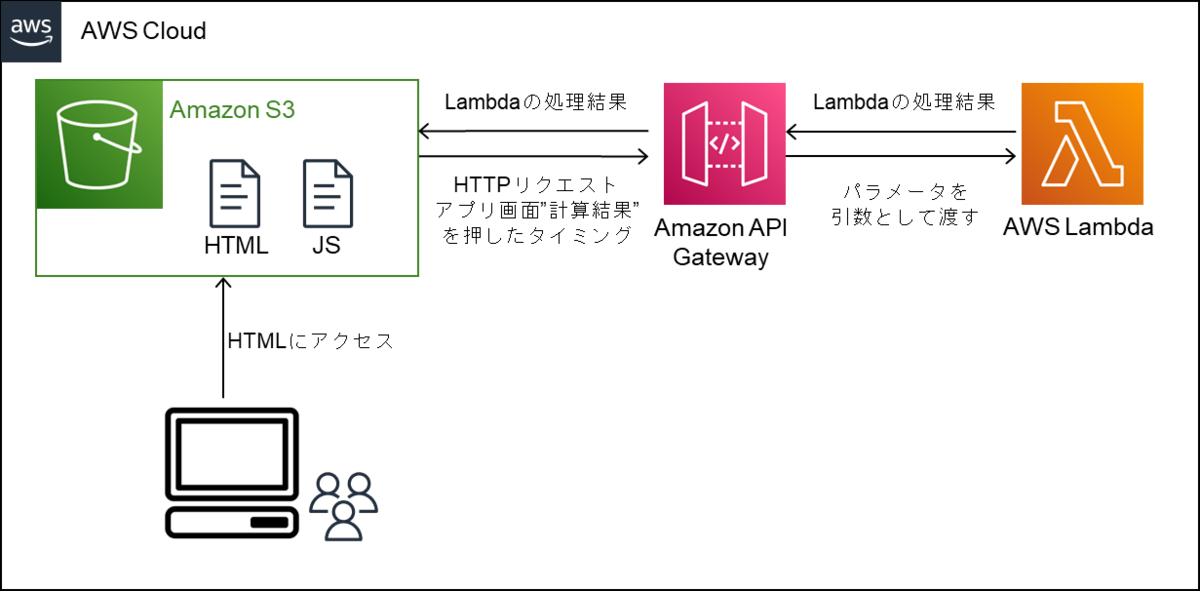
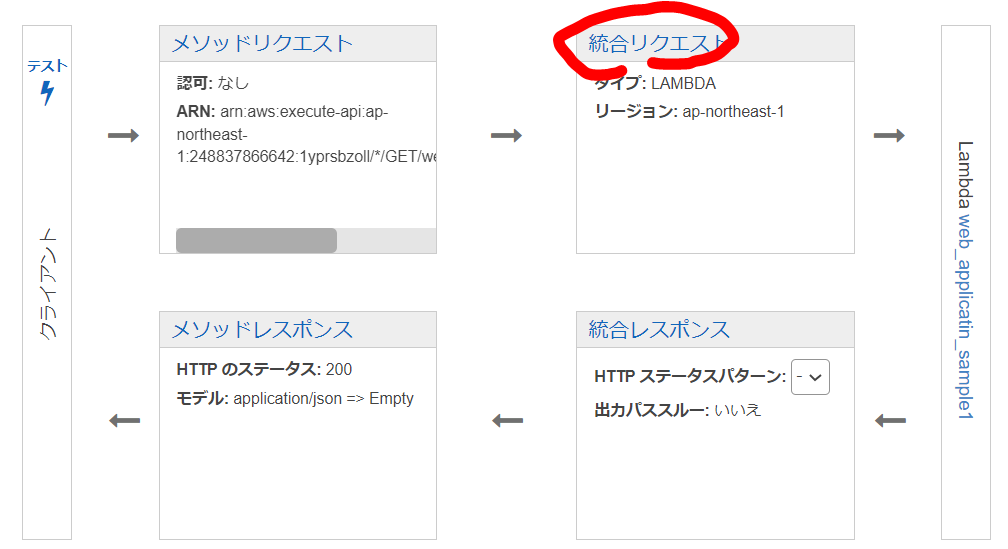
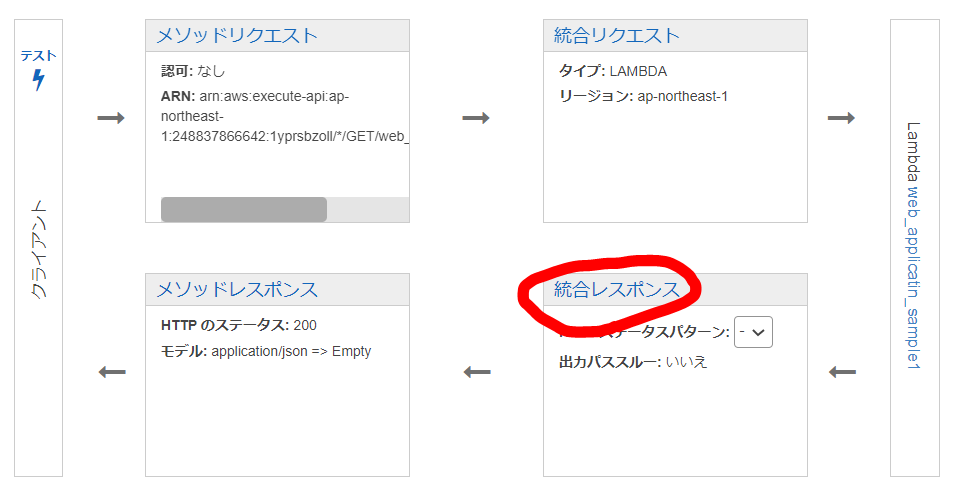
統合リクエスト設定
統合リクエストは、API Gatewayがバックエンドに送るHTTPリクエストで、クライアントから送信されたリクエストデータを渡して、必要に応じて変更します。今回はAWS Lambdaに渡すことを前提とします。設定方法は、以下にまとめられています。
API Gateway で Lambda プロキシ統合を設定する - Amazon API Gateway

メソッドリクエストから、クエリパラメータを受け取って、Lambdaに渡したい場合は、クエリパラメータを登録する必要がある。
統合リクエストから、マッピングテンプレートを登録する。今回は、JSON形式で受け取りたいので、以下の通り3つのパラメータ(my_param1, my_param2, my_param3)をもらう設定を追加。

クエリパラメータの設定方法
URLにクエリパラメータを付与する場合は、ルールに従って以下のように書く必要がある。
- パラメータはURLの後に「?」をつけて記載
- 各パラメータは「名前=値」で記載
- 複数パラメータを付与する場合は、「&」で分ける
書き方(3つのパラメータmy_param1, my_param2, my_param3を付与するケース)
URL(https://*******)?my_param1=1&my_param2=2&my_param3=3
URLはデプロイしたHTTPメソッドのエンドポイントに設定する。

エンドポイントとは、クライアントとAPIとが通信をするための窓口であり、APIのリクエスト先になる。
プロキシ統合設定について
HTTPメソッドを作成する際に、「Lambdaプロキシ統合の使用」というチェックボックスがあり、この役割を説明する。

詳しくは以下にまとめられていたが、以下のように理解しました。
qiita.com
動作を確認
環境設定に関しては、以下の通りで、Lambda関数は「statusCode」「body("Hello World")」「event(リクエスト)」を返す関数であり、API Gateway側ではANYメソッドがリクエストデータをそのままLambda関数に渡す設定になっている。プロキシ統合は非統合の設定。
Lambda関数
import json
def lambda_handler(event, context):
return {
'statusCode': 200,
'body': json.dumps('Hello World'),
'event': json.dumps(event)
}
AWS API Gateway

GET
ローカルにて以下コードを実行して、出力結果を確認した。
import requests
import json
pattern = "GET"
URL = r"エンドポイント"
payload = {'my_param1':"1", 'my_param2':2, 'my_param3':3}
if pattern == "GET":
print("GET")
response = requests.get(URL, params=payload)
data = response.json()
print ("json", json.dumps(data, indent=4))
print("status_code",response.status_code) # ステータスコード取得
print("HTML_text", response.text) # HTMLを文字列で取得
print("binary", response.content) # HTMLをバイナリ形式で取得
出力結果は以下の通りで、eventは何もない状態で返されている。クエリとして、3つのパラメータを送付しているが、クエリパラメータを受け取る設定にしていないため、こういった現象が起きている。
GET
json {
"statusCode": 200,
"body": "\"Hello World\"",
"event": "{}"
}
status_code 200
HTML_text {"statusCode": 200, "body": "\"Hello World\"", "event": "{}"}
binary b'{"statusCode": 200, "body": "\\"Hello World\\"", "event": "{}"}'
上記で説明した通り、統合リクエスト設定にてマッピングテンプレートを設定すると、以下の通り、受け取ることができて、Lambda関数に適切に渡されていることが確認できる。
# マッピングテンプレート設定後
GET
json {
"statusCode": 200,
"event": "{\"my_param1\": \"1\", \"my_param2\": \"2\", \"my_param3\": \"3\"}"
}
status_code 200
HTML_text {"statusCode": 200, "body": "\"Hello World\"", "event": "{\"my_param1\": \"1\", \"my_param2\": \"2\", \"my_param3\": \"3\"}"}
binary b'{"statusCode": 200, "body": "\\"Hello World\\"", "event": "{\\"my_param1\\": \\"1\\", \\"my_param2\\": \\"2\\", \\"my_param3\\": \\"3\\"}"}'
POST
ローカルにて以下コードを実行して、出力結果を確認した。
import requests
import json
pattern = "POST"
URL = r"エンドポイント"
payload = {'my_param1':"1", 'my_param2':2, 'my_param3':3}
if pattern == "POST":
print("POST")
response = requests.post(URL, data=json.dumps(payload))
data = response.json()
print ("json", json.dumps(data, indent=4))
print("status_code",response.status_code) # ステータスコード取得
print("HTML_text", response.text) # HTMLを文字列で取得
print("binary", response.content) # HTMLをバイナリ形式で取得
出力結果は以下の通りで、POSTメソッドの場合はマッピングテンプレートの設定をせずパラメータを送付して、Lambda関数に適切に渡されていることが確認できる。
POST
json {
"statusCode": 200,
"body": "\"Hello World\"",
"event": "{\"my_param1\": \"1\", \"my_param2\": 2, \"my_param3\": 3}"
}
status_code 200
HTML_text {"statusCode": 200, "body": "\"Hello World\"", "event": "{\"my_param1\": \"1\", \"my_param2\": 2, \"my_param3\": 3}"}
binary b'{"statusCode": 200, "body": "\\"Hello World\\"", "event": "{\\"my_param1\\": \\"1\\", \\"my_param2\\": 2, \\"my_param3\\": 3}"}'
HEAD
ローカルにて以下コードを実行して、出力結果を確認した。
import requests
import json
pattern = "HEAD"
URL = r"エンドポイント"
payload = {'my_param1':"1", 'my_param2':2, 'my_param3':3}
if pattern == "HEAD":
print("HEAD")
response = requests.head(URL)
#data = response.json()
#print ("json", json.dumps(data, indent=4))
print(response)
print("status_code",response.status_code) # ステータスコード取得
print("HTML_text", response.text) # HTMLを文字列で取得
print("binary", response.content) # HTMLをバイナリ形式で取得
出力結果は以下の通りで、HEADメソッドでは、レスポンスボディを返さないため、 response.content などでレスポンスボディを取得することはできません。HEADメソッドは、サーバーからのレスポンスボディを取得することがないため、GETメソッドよりも高速にリソースの存在確認を行うことができます。
HEAD
<Response [200]>
status_code 200
HTML_text
binary b''
他のメソッドに関しては、実際にWEBアプリを作った際に色々と確認しようと思う。一旦はここまで。