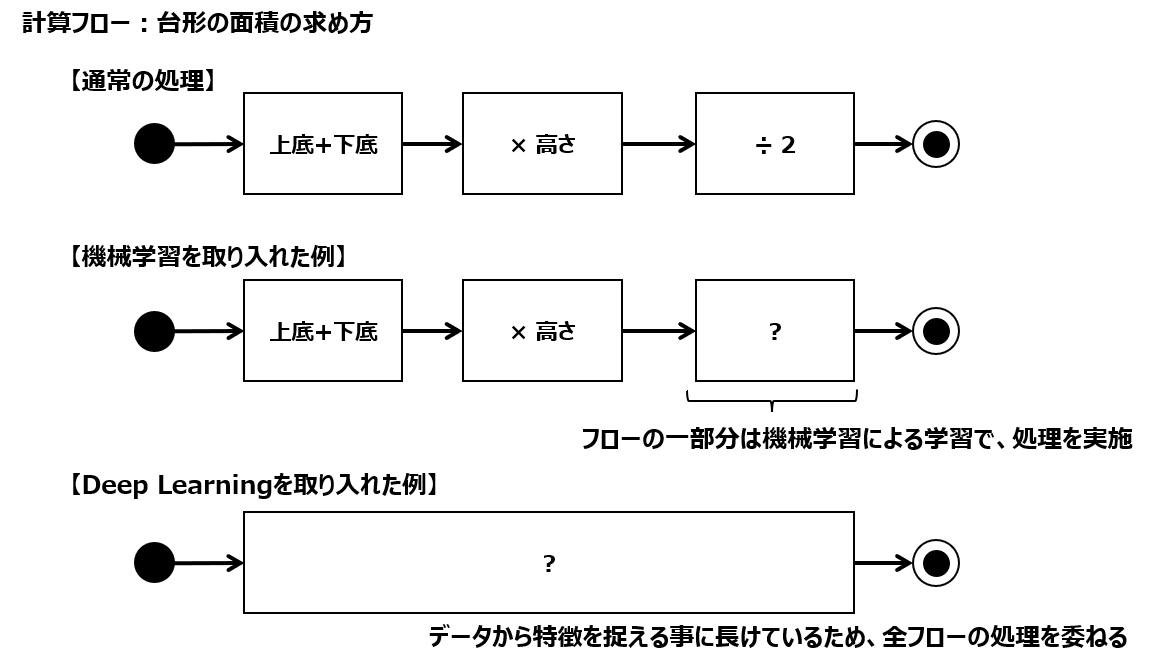
目次
ニューロンと人工ニューロンとは
パーセプトロンの前に、本アルゴリズムのモデルとなったニューロンについてまとめます。
ニューロンは神経系を構成する基本単位であり、体の中で情報の伝達に使われいる。
人工ニューロン(形式ニューロン)とは、それを模擬したものであり、1943年にウォーレン・マカロックとウォルター・ピッツが発表した。
人工ニューロンの仕組み

単純な論理回路の設計
人工ニューロンの活用例として、簡単な論理回路を作成してみます。
簡単な実装
表:ANDゲートの真理値表
| x1 | x2 | y |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 1 | 1 |
これをpythonにて実装する。
def AND(x1, x2, b):
w1, w2, theta = 0.5, 0.5, 1
temp = x1*w1+x2*w2+b*1
if temp <= theta:
return 0
elif temp > theta:
return 1
AND(0,0,0)#出力0
AND(1,0,0)#出力0
AND(0,1,0)#出力0
AND(1,1,0)#出力1期待通りの出力が得られています。
同様にORゲート, NANDゲートは作成できるので、ここでは割愛します。
作成できる論理回路の限界
上記の通り、論理回路を実装することができたのですが、排他的論理和XORだけは実装ができません。
実際にグラフを作成してその理由を確認します。
表:XORゲートの真理値表
| x1 | x2 | y |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 0 |
これを図で示すと以下の通りです。
図:人工ニューロンの可視化

- 赤丸:1が出力する
- 青四角:0が出力する
しきい値の例を黒線で示し、黒線からx1, x2軸側の範囲が0出力領域、それ以外を1出力領域とする
これを上記通り出力しようとしても、しきい値は線形的にしか引くことができない為不可能。
これに対応するためには、非線形な線でしきい値を設定する、複数の直線で切り分ける方法があります。
ただ、論理回路の作り方に詳しい人はご存じの通り、XORゲートも複数の論理回路の組み合わせで表現が可能です。
これは上記で述べた後者の方法になります。前者の方法は今後説明していくとして、人工ニューロンを組み合わせる(多層にする)考え方でXORゲートを実装することができます。
つまり、人工ニューロンの組み合わせでXORゲートような少し複雑なパターンも表現できるということです。
※層を複数に重ねた人工ニューロンを多層パーセプトロンということがあります。
グラフ出力用のコード
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(5, 5))
x1_0 = [0, 1]
x2_0 = [0, 1]
x1_1 = [0, 1]
x2_1 = [1, 0]
plt.scatter(x1_0, x2_0, marker=",")
plt.scatter(x1_1, x2_1, marker="o", color="red")
plt.plot([-1, 1.5], [1.5,-1], color="black")
plt.xlim(-1,3)
plt.ylim(-1,3)
plt.xlabel("x1")
plt.ylabel("x2")